
ComfyUIで画像生成モデル「Ideogram 4」を使う方法を紹介します。
Ideogram 4は、Ideogramが公開した初のオープンウェイトの画像生成モデルです。
ComfyUIは0.24.0からこのIdeogram 4にネイティブ対応していて、追加のカスタムノードを入れなくても使えます。
Ideogram 4とは?
Ideogram 4は、Ideogramがゼロから学習したテキストから画像の基盤モデルです。
既存モデルの追加学習ではなく、新規に作られたフローマッチング型のモデルで、パラメータは9.3B。
いちばんの特徴は画像内の文字描画の正確さで、看板やロゴ、キャプションなどを破綻なく出せること。
プロンプトは構造化JSON(後述)で書くと、構図や配色、文字の位置まで細かく指定可能です。
主な特徴
- オープンウェイトのテキストから画像モデル(9.3B)
- 画像内テキストの描画がオープンモデル最高クラス
- 構造化JSONプロンプトで構図やスタイル、配色、文字配置を細かく制御できる
- バウンディングボックス指定で被写体や文字の位置を指定できる
- 256から2048pxまで、16の倍数で自由な解像度やアスペクト比に対応
- ComfyUI 0.24.0以降でネイティブ対応(カスタムノード不要)
ComfyUIでIdeogram 4を使う方法
ComfyUIを最新に更新する
Ideogram 4はComfyUI 0.24.0以降でネイティブ対応しています。
古いバージョンだとノードが出てこないので、まずComfyUIを最新に更新してください。
デスクトップ版やクラウド版は安定版リリースに追従するので、反映が少し遅れることがあります。
ワークフローを読み込む
ComfyUIのテンプレートから、Ideogram 4のテキストから画像のワークフローを読み込みます。
テンプレートはComfyUIメニューのワークフローテンプレートから選択可能です。
Githubからもダウンロードできます。
image_ideogram4_t2i.json(GitHub)
モデルの用意
それぞれ下記のファイルをダウンロードして、対応するフォルダに置いてください。
・拡散モデル(本体)
- ideogram4_fp8_scaled.safetensors … プロンプトに沿って描く本体側のモデル
- ideogram4_unconditional_fp8_scaled.safetensors … プロンプトを外した無条件側のモデル
Ideogram 4はこの2つを同時に使うガイダンス方式(dual-branch CFG)なので、両方ともダウンロードして同じフォルダに置きます。
ComfyUI\models\diffusion_models・テキストエンコーダー
qwen3vl_8b_fp8_scaled.safetensors
ComfyUI\models\text_encoders・VAE
ComfyUI\models\vaeノードの設定&実行
ワークフローを読み込んだら、モデルを指定するだけです。
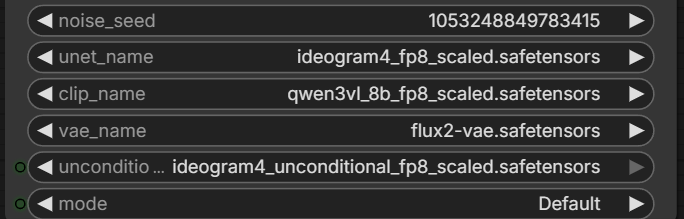
Text to Image (Ideogram v4)
ダウンロードしたモデルを各ローダで選びます。
拡散モデルにideogram4_fp8_scaled、無条件側にideogram4_unconditional_fp8_scaled、テキストエンコーダーにqwen3vl_8b_fp8_scaled、VAEにflux2-vae。
mode
モードは生成の速さと品質のプリセットを選べるものです。

| プリセット | ステップ数 | 用途 |
|---|---|---|
| Turbo | 12 | 速さ重視のお試し |
| Default | 20 | 標準 |
| Quality | 48 | 品質重視 |
プロンプト
Ideogram 4は構造化JSONで書くと、構図やスタイル、配色、文字を細かく指定できます。
プレーンな文章でも生成できますが、JSONのほうが思い通りの結果になりやすいです。
{
"high_level_description": "夜のネオン街を背景に、赤いジャケットの女性が立つポスター",
"style_description": {
"aesthetics": "レトロなポスター調、高コントラスト",
"color_palette": ["#1E73BE", "#C82A2A", "#FDFDFD"]
},
"compositional_deconstruction": {
"background": "雨に濡れたネオンの街並み",
"elements": [
{ "type": "text", "bbox": [50, 100, 200, 900], "text": "MIDNIGHT", "desc": "上部に大きな白い見出し文字" }
]
}
}ただこの内容だとセーフティーフィルターが作動して生成できませんでした。
NSFW系入れてなくてこの結果なので、フィルターは厳しめかもしれません。

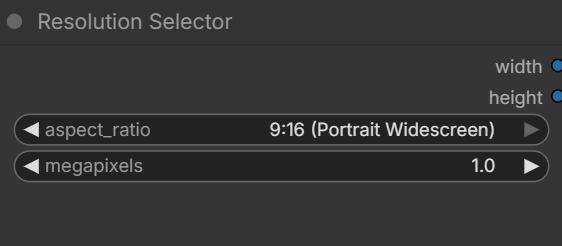
ResolutionSelector(解像度)
アスペクト比とmegapixels(画像の大きさ)を選びます。
Ideogram4 Caption Prompt Template/Preview as Text
ここは生成したい内容を書くとLLMに与えるPromptを出力してくれるものです。
ここだけ実行したい場合はText to Image (Ideogram v4)のサブグラフはバイパスしてください。
「Ideogram4 Caption Prompt Template」に作りたいイメージを入力して実行。
入力したイメージと、Preview as Textの出力両方をChatGPTなどのLLMに渡すと入れると、JSON形式のプロンプトに整えてくれるというもの。

これをPromptとして使えばより詳細な画像が生成できるようです。
設定が終わったら、ComfyUIのRunを押して実行します。
結果
PromptはAIに考えてもらったもので、生成時間はmode:defaultで約1分でした。
文字は再現出来てますが、手を振るとかはあまり反映されていません。

{"high_level_description":"A retro mascot poster of a friendly round robot waving, with bold 3D puffy letters spelling 'HELLO' above it, on a bright teal background.","style_description":{"aesthetics":"Retro mascot illustration, clean flat vector poster with subtle paper grain","lighting":"Even bright studio lighting with soft shadows","color_palette":["#13A89E","#FFD23F","#FF6B6B","#FFFFFF","#1A1A1A"]},"compositional_deconstruction":{"background":"A flat bright teal background with faint halftone dots and a subtle paper grain texture.","elements":[{"type":"text","bbox":[80,150,300,850],"text":"HELLO","desc":"Large rounded 3D puffy white letters spelling 'HELLO' across the upper area"},{"type":"obj","bbox":[350,280,880,720],"desc":"A friendly round robot mascot with one big glowing screen-eye, a short antenna, and stubby arms waving, colored yellow and white with red accents"}]}}生成時間は約3分になりますが、mode:qualityにすると手を振る感じもちゃんと再現されました。

まとめ
jsonで複雑な指定しつつテキストも綺麗に生成できるので、ブログのサムネとかそういう用途にはいいかもしれません。
ただフィルターが厳しいので生成できる内容は少し限られてしまいそうです。
以上Ideogram 4の使い方を紹介しました。
参考になれば幸いです。

