
先日Vast.aiでQwen ImageのLoRA作成をしたときにai-toolkitを初めて試しました。

最新モデルへの対応も早く、かなり扱いやすかったです。
私自身まだあまり分かってない部分もあるので、アウトプット兼ねてローカルでai-toolkitを使う方法をまとめてみました。
この記事ではローカルにAI Toolkitをインストールする方法と、実際にFluxモデルでLoRA作成するところまでを解説します。
- AI Toolkit(ai-toolkit)の特徴と対応モデル(FLUX・SDXL・Qwen・Wanなど)
- インストール方法3通り(Easy-Install・手動クローン・Stability Matrix)
- LoRA学習の手順と設定(Dataset作成〜ジョブ設定〜学習〜LoRAの出力先)
ai-toolkitとは?
AI Toolkitは、Ostrisが開発したオープンソースのトレーニングツールキットです。
主にdiffusionモデルのLoRA/LoKrが作成できるもの。
対応モデルも幅広くFLUX、SDXL、Qwen Image、Wanなど。
実際に触った感じGUIも非常に使いやすく、複雑な操作や設定がほとんどありません。
LoRA作成ツールはいろいろありますが、環境設定も学習もとにかく簡単にやりたいという方には合うと思います。
ただモデルに応じてそれなりにスペックは必要だし、設定によって学習速度が遅くなることもあります。
主な対応モデルは以下の通りです。
| モデル | 用途・備考 |
|---|---|
| FLUX.1(dev / schnell) | 高品質な画像生成モデル。利用に認証が必要 |
| FLUX.2 | FLUXの新世代。要求スペックは高め |
| SDXL | 定番のStable Diffusion系 |
| Qwen Image | Alibaba系の画像生成モデル |
| Z-Image | 比較的軽量で扱いやすいモデル |
| Wan | 動画生成モデル |
対応モデルは更新で増えています。
最新は公式リポジトリで確認してみてください。
ostris/ai-toolkit: The ultimate training toolkit for finetuning diffusion models
必要なスペック・動作環境
AI Toolkitで快適に学習するには、モデルに応じたGPU性能(特にVRAM)が必要です。
下表はあくまで目安で、実際の必要量は解像度やバッチサイズ、設定によって変わります。
| モデル | VRAMの目安 |
|---|---|
| SDXL | 約12GB |
| FLUX.1(dev) | 24GB前後 |
| Qwen Image / Wan | 24GB前後 |
| FLUX.2(dev) | 24GB前後 |
なお、Fluxはこの記事で試してますが、時間はかかるものの VRAM16GB / RAM64GB でも学習は可能です。
ai-toolkitのインストール
事前準備
インストール方法は主に3つです。
いずれの方法でも、基本的にPython3.10以上・git・Node.js18以上が必要です(後述のAI-Toolkit-Easy-Installなら不足分を自動で入れてくれます)。
①AI-Toolkit-Easy-Install
公式のrepoで紹介されているAI-Toolkit-Easy-Installというインストーラー用のbatファイルを使う方法です。
以下のリポジトリのDownload the latest release ▶️HEREの部分がリンクになってるのでそこからダウンロードしてください。
zip形式なので任意の場所で解凍します。

なお、Program FilesやC直下などのシステムフォルダじゃない場所かつフォルダ名にスペースは含めない方が良いそうです。
中にbatファイルがあるのでそれを実行します。
batファイルも管理者権限ではなく普通に実行してくださいとのことです。

実行するとgitやnode.jsのインストール確認画面が出るので許可して進めます。
Installation Completeと出たら完了です。
起動は同じフォルダに作られるStart-AI-Toolkit.batを実行するだけです。
コンソールに表示されるLocalのURLをCtrl+左クリックで開いてください。

②手動でクローン
事前にPython3.10以上、git、Node.js18以上のインストールが必要です。



ターミナルを開いて、インストールしたいディレクトリに移動してからコマンドを順に実行します。
git clone https://github.com/ostris/ai-toolkit.git
cd ai-toolkit
python -m venv venv
.\venv\Scripts\activate
pip install --no-cache-dir torch==2.7.0 torchvision==0.22.0 torchaudio==2.7.0 --index-url https://download.pytorch.org/whl/cu126
pip install -r requirements.txtuiフォルダに移動して起動します。
cd ui
npm run build_and_startコンソールに表示されるLocalのURLをCtrl+左クリックで開いてください。

二回目以降は仮想環境アクティベートしてstartのみで起動できます。
ビルドは必要ありません。
npm run start③Stability Matrix
Stability Matrixのインストールはこちらを参考にしてください。
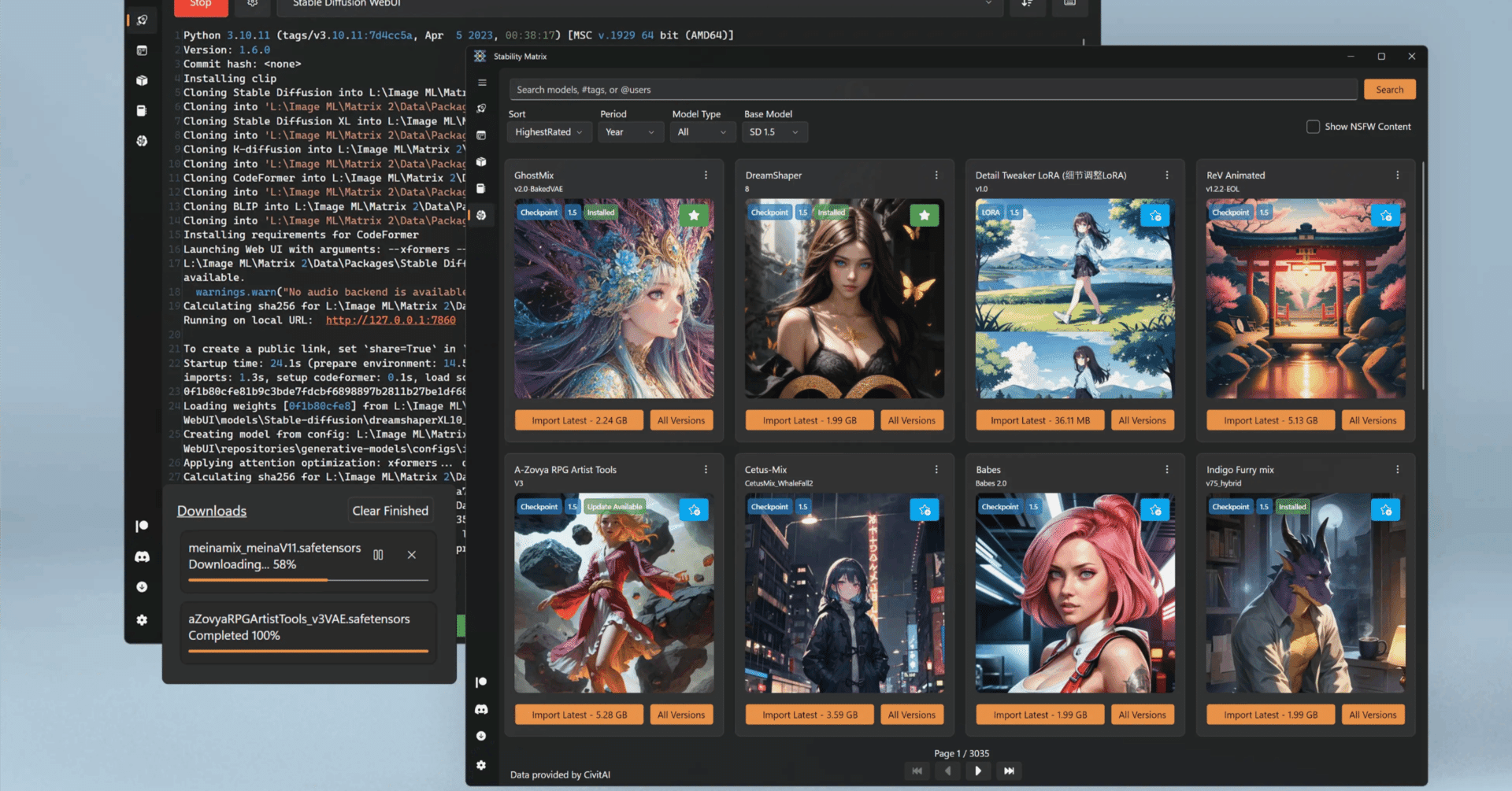
Stability Matrixを起動したらパッケージを開き、パッケージの追加をクリック。
trainingタブでai-toolkitをクリック。
インストールボタンが表示されるのでそのままインストールしてください。
インストールが終わったらパッケージ一覧から起動できます。
なお、自動起動の引数などはないようで、stabilitymatrixもコンソールからURLクリックで開く必要があります。
ai-toolkitの使い方
Setting
もし認証が必要なモデル(Fluxなど)をhuggingface経由でダウンロードする場合は、認証とトークンが必要です。
不要ならここは飛ばしてください。
まずhuggingfaceのアカウントを取得します。

ログイン後、使用するモデルのページで利用規約などに同意します。
black-forest-labs/FLUX.1-dev · Hugging Face
次にアカウントのアイコンからAccess Tokensを開きます。
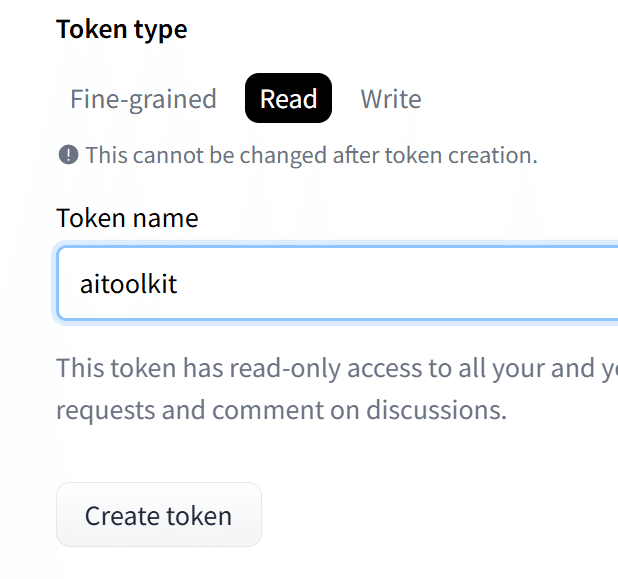
Create new tokenをクリック。

Readタブで任意の名前を付けてCreate tokenをクリック。
Tokenが表示されるのでそれをコピーします。
AITOOLKITの左メニューからsettingを開き、tokenを入力してSave settingで保存します。

これで認証が必要なhuggingfaceのリポジトリからモデルのダウンロードや読み込みが行えます。
Datasets
次にDatasetsに移動します。
学習に使用する画像とキャプションを設定するものです。
右上のNew Datasetをクリック。
任意の名前を付けてcreateをクリック。
こんな画面になるのであとはここに学習する画像とキャプションをD&Dします。
これでDatasetの準備は完了です。

New job
次にジョブを作成します。
学習時の設定を決めるものです。
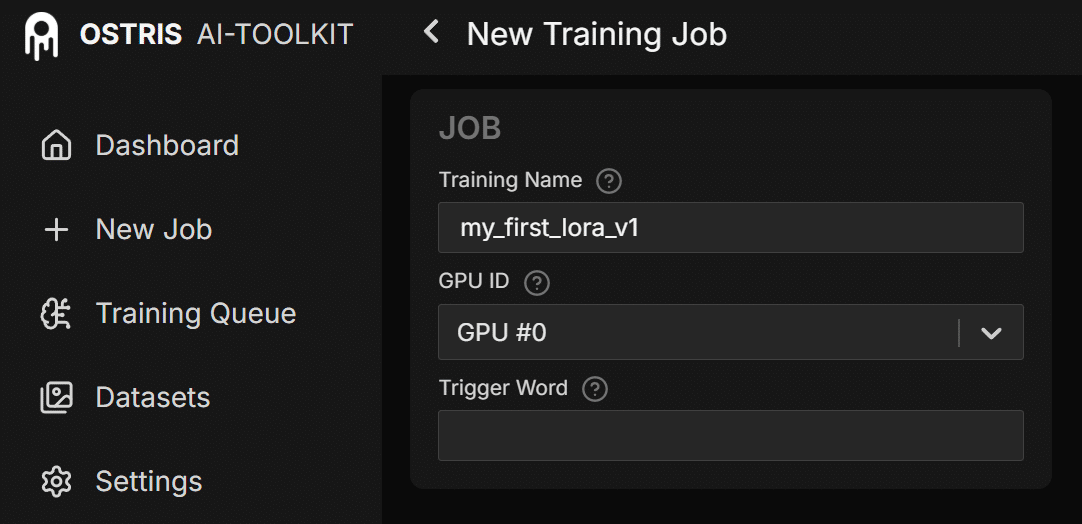
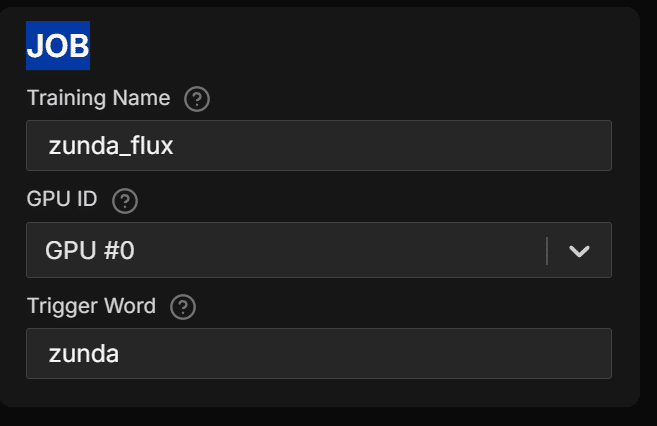
JOB
training nameはLoRAのファイル名になるものです。
trigger wordはLoRA呼び出し時にプロンプトで使うものという認識でしたが、人によって入れてない方もいるのでよくわかってないです。
とりあえず入れときました。
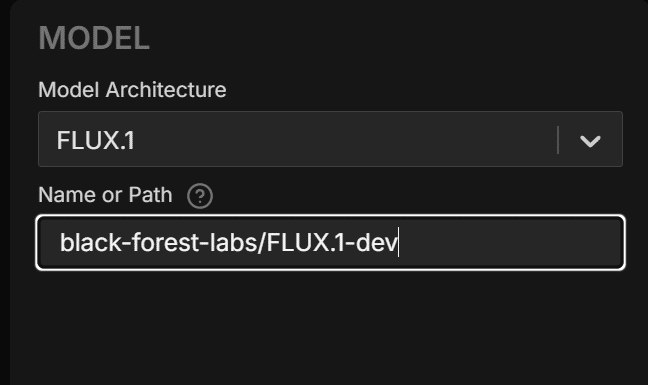
MODEL
学習するベースモデルとそのパスです。
デフォルトだとhuggingfaceのリポジトリが設定されています。
ローカルモデルがあるならそのパスを指定すればそれを使用できます。
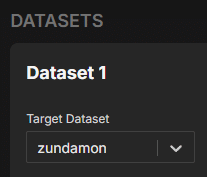
Dataset
上記で作成したDatasetの名前です。
学習するDatasetと合ってるか確認してください。
その他
他は学習するモデルやPCスペックによります。
Qwenとかwanについては公式が動画出してるのでそれ見るのが無難です。

notebooklm使えば日本語で解説もしてくれます。

今回Fluxをデフォルトのまま試したのですが、それだとほぼ進まなかったので、一部調整しました。
・learning rate
Qwenの公式動画だと進みが遅くてここを0.0002にしていたので真似しました。

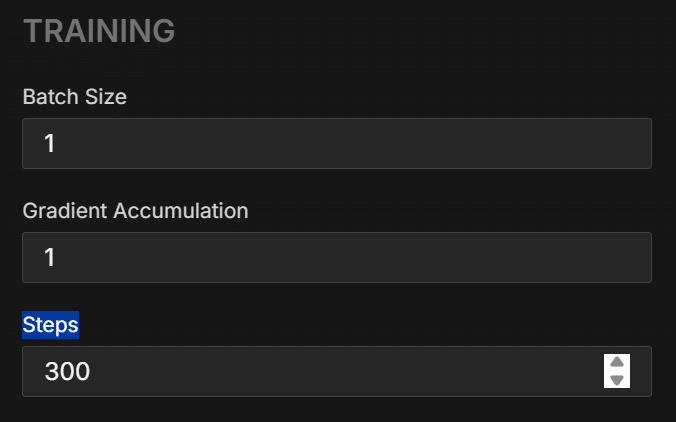
・Steps
一回Linear RankとかOptimizerいじって1500stepでやったら10時間くらいかかりました。
それでいて出来たLoRAが全然使えないものでした。
さすがにもう一回やるのが億劫だったのでデフォルトに近い設定で300stepsにしました。
ここはPCスペックや求めるクオリティ、モデルによると思います。
・Cache Text Embeddings
テキストエンコーダーの処理を最初にやってキャッシュすることでGPUの処理を軽減できるものだそうです。
一応ONにしました。

・Disable Sampling
サンプル生成をオフにできるものでLoRA学習には影響しません。
設定したプロンプトと頻度でサンプル画像を生成し、LoRAの途中経過を確認できるもの。
今回は処理速度重視だったのでオフにしました。
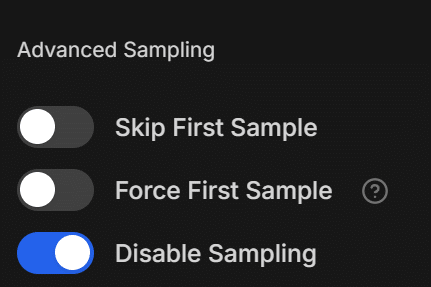
sample生成したい方はSample Everyで何stepごとに生成するか、Sample Promptsで生成するサンプルのプロンプトと個数を設定できます。
通常はミス防止などのためONの方が良いと思われます。
学習開始
設定できたら右上のcreate jobをクリックします。

ページ移動するので、右上の▷をクリックします。

そうすると学習が始まり、Logが表示されます。
Proglessバーが最後まで進み、logもSaved checkpoint~と出れば学習完了です。


基本outputフォルダに .safetensors で保存されます。
AI-Toolkit\output\train_name\train_name.safetensorsGUI右下にあるChackpointからもダウンロード可能です。
終了時の注意
stabilitymatrixはそのままストップ押せば問題ありません。

ただAI-Toolkit-Easy-Installや手動インストールした場合は、そのままターミナルを消すとポートが使われたままになります。
二回目の起動に失敗するので、ターミナルでCtrl+C押して停止した方が良さそうです。
この黒い画面上でCtrl+C押せばOK。
もしCtrl+Cで止めず消してしまったあとポートを切断したい場合は、コマンドプロンプトで以下を実行します。
netstat -aon | findstr :8675こんな表示がでます。

一番右の数字を
taskkill /PID <PID> /F
↓
taskkill /PID 16160 /Fこれでポートの切断が可能です。
生成結果
イラストリアスで生成したzundamon20枚をflux(300step)で学習させたLoRAです。
耳とか若干甘いですが、300stepにしては再現出来てる方かなと思います。
ちなみに画像20枚・300STEPで4時間くらいかかりました。

作ったLoRAの使い方(ComfyUI / WebUI)
学習が終わると、safetensors形式のLoRAファイルが出力されます。
使い方は通常のLoRAと同じで、お使いのツールのLoRAフォルダに置くだけです。
ComfyUIなら「models/loras」、WebUI(Forgeなど)なら「models/Lora」に保存します。
あとはLoRAを読み込み、学習時にtrigger wordを設定した場合はプロンプトに入れて呼び出せます。
つまずきやすいポイント
試した範囲で、つまずきやすかった点をまとめます。
・学習が全然進まない・遅い
モデルやスペックによっては、デフォルト設定だとほぼ進まないことがあります。
learning rateやStepsを調整してみてください。
・VRAM不足でエラーになる
これはスペックによって仕方ない部分もあります。
画像の解像度やバッチサイズを下げることで改善する場合もありますが、そもそも学習ができない場合はクラウドGPUやPC環境見直す必要があるかもしれません。
・モデルがダウンロードできない(認証エラー)
FLUXなど認証が必要なモデルは、Hugging Faceのトークン設定と、モデルページでの規約同意が必要です。
・2回目の起動に失敗する
ターミナルをそのまま閉じるとポートが使われたままになります。
停止はCtrl+Cで行ってください(詳しくは上の「終了時の注意」を参照)。
まとめ
個人的にはインストールや操作含め、今まで使ったLoRA作成ツールの中で一番簡単な印象でした。
画像とキャプションのセットもD&Dするだけだし、パラメータもモデル選んだら自動で変わるし、学習までの準備が本当に楽だと思います。
サンプル生成をONにすれば学習ミスも防げるし、途中で止めて設定変えて再開もできるので、興味ある方はぜひ使ってみてください。
以上ai-toolkitの使い方を紹介しました。
参考になれば幸いです。

