
今からStable Diffusionで画像生成AIを始めたいという方に向けて、Stable Diffusion Web UI AUTOMATIC1111(以下A1111)の使い方をご紹介します。
A1111(Stable Diffusion WebUI)とは?
A1111は、画像生成AIの「Stable Diffusion」をローカルのパソコンで動かせるWeb UIです。
正式名称はStable Diffusion Web UI(AUTOMATIC1111版)。
Pythonの「gradio」というライブラリで作られていて、ブラウザ上の画面からプロンプトを打つだけで画像を生成できます。
Stable Diffusion自体は2022年に登場した「テキストから画像を作る」モデルですが、それ単体だと扱いづらいので、こういうWeb UIを被せて使うのが一般的です。
派生UIにはForge、ComfyUI、Fooocus、SwarmUIなどがありますが、A1111はその中でもおそらく一番最初に公開された定番ツールです。
拡張機能を入れれば、生成の効率化や自分好みのカスタマイズもできます。
2026年のA1111と「Forge」について
A1111本体(AUTOMATIC1111)の更新は、現在止まっています。(26年6月時点)
その代わりとしてSDWebUI Forgeが登場し、その後Forgeがさらに派生してreForge、Forge classic/NeoなどのWeb UIが開発されてきました。
これらはA1111とほぼ同じ操作感のまま、生成速度の向上や新しいモデルなどに対応しています。
なのでWebUI入門としてA1111から始めるのは全然ありですが、新モデルや最新技術を使いたい場合は、最初からForge系で始めるか、慣れてから移行するのをお勧めします。
多少の違いはあるものの、画面や基本操作はA1111とほぼ共通なので、途中で移行してもそのまま操作できると思います。
A1111のインストール方法
インストール方法は2通りありますが、本記事ではgitとpythonを使う「手動インストール」で進めます。
出回っている解説のほとんどがこの方法なので、詰まったときも情報を探しやすいためです。
git・pythonでインストール
先にGitとPythonを入れてから、A1111をクローンします。
・Git for Windows
Gitはコードの変更履歴などを保存できる分散型バージョン管理システムです。
インストールすることでGitHubとのやり取りもスムーズになります。
- 公式サイトにアクセス
- インストーラを「Download」
- 実行してすべてデフォルトのままNext連打
ターミナルやcmdで git -v でバージョンが表示されればインストールは完了です。

・Python 3.10.6
pythonはプログラミング言語の一つです。
このSDWebUIはほぼpythonで作られているため、動かすためにインストールが必要です。
- 公式サイトに移動
- 「Windows installer (64-bit)」をダウンロード
- 「Add Python to PATH」にチェックを入れる
- 「Install Now」で進める
・A1111のクローンと起動
GitHubからA1111をクローンします。任意のパスで以下を実行してください。
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.gitstable-diffusion-webuiフォルダの中のwebui-user.batを実行すると、必要なものが自動でインストールされ、終わるとWebUIが開きます。
ただし、現在更新されてないため、一部自身で修正が必要です。
エラーで起動出来ない場合の対処法
2026年6月時点で、2つのエラーで起動ができなくなっています。
「No module named ‘pkg_resources’」が出る場合(CLIPのインストール失敗)
1つはNo module named ‘pkg_resources’というエラー。
これは古いCLIPのビルド処理に、隔離ビルドが「新しすぎるsetuptools」を持ち込んで衝突しているそうです。
なのでsetuptools・wheelのバージョンを指定してインストール、そのあとCLIPをインストールすれば起動できます。
stable-diffusion-webui のフォルダでpowershellを開き、以下を順に実行してください。
.\venv\Scripts\python.exe -m pip install --force-reinstall setuptools==69.5.1 wheel==0.45.1
.\venv\Scripts\python.exe -m pip install --no-build-isolation "https://github.com/openai/CLIP/archive/d50d76daa670286dd6cacf3bcd80b5e4823fc8e1.zip"「Couldn’t clone Stable Diffusion」/ error code 128 が出る場合(配布元が消えている)
もう1つは、配布元が消えているものをインストールしようとするため、そのせいで起動できない状態になっているもの。
コンソールには以下のように表示されます。
RuntimeError: Couldn't clone Stable Diffusion.
remote: Repository not found.
fatal: repository 'https://github.com/Stability-AI/stablediffusion.git/' not found
Error code: 128なので自分で指定が必要です。
webui-user.batをメモ帳などで開いて以下を追加してください。
set STABLE_DIFFUSION_REPO=https://github.com/w-e-w/stablediffusion.git
保存したあと、webui-user.batを実行すればA1111を開けるようになります。
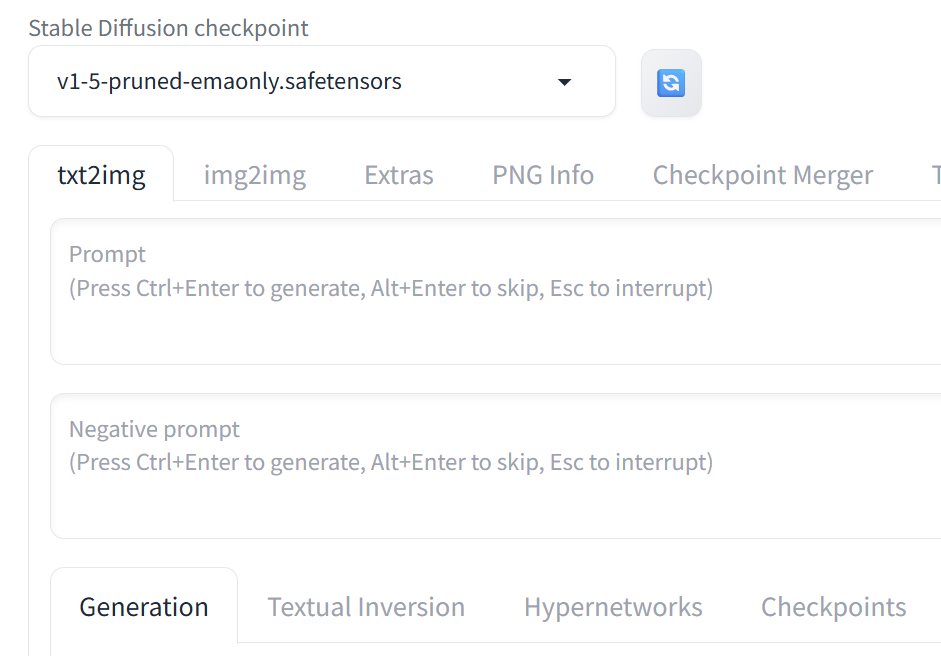
ブラウザでこんな画面が開けばインストール完了です。
パッケージ版(簡単に試したい人向け)
GitやPythonを用意せず、ワンクリックで使えるパッケージ版(sd.webui.zip)もあります。
下のページからzipを落として解凍し、update.bat→run.batの順に実行すれば動きます(日本語を含まないパスに置くのが無難です)。
https://github.com/AUTOMATIC1111/stable-diffusion-webui/releases/tag/v1.0.0-pre
ただしパッケージ版はモデルを置くパスなどフォルダ構成が手動版と違い、出回っている解説も少なめです。
なので基本はGit・pythonを使ったインストールを推奨します。
A1111の基本的な使い方
とりあえず画像生成してみる
起動するとこんな画面が表示されます。
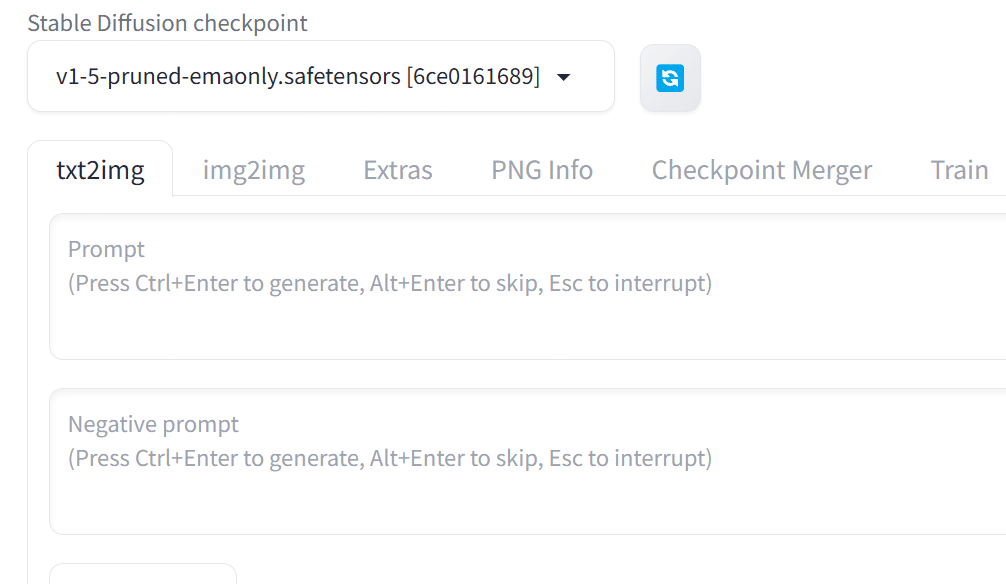
一番上のプルダウンはモデルを選択する場所です。
使用モデルによって生成できる画像の種類やテイストが異なります。
その下の入力欄はどんな画像を生成するかテキストで指示するものです。
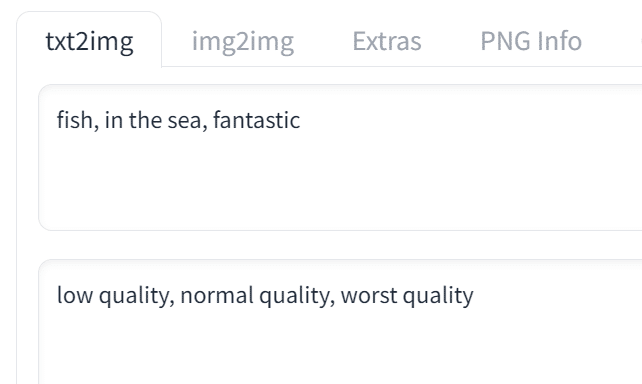
基本は英単語をカンマで区切り、上のpromptには生成したいもの、下のnegative promptには生成したくないものを入力します。
prompt:fish, in the sea, fantastic
negative prompt:low quality, normal quality, worst quality negative promptに入れているのは、低クオリティの画像を避けるためのものです。
入力し終わったら、Generateボタンで画像生成の処理が始まります。
・生成した画像

生成した画像は以下のパスに保存されます。
stable-diffusion-webui\outputプロンプトの基礎
プロンプトでは括弧や値を使うことで、要素の強弱やステップ数を指定することができます。
・丸括弧
赤という色を強調したい場合、(red)のように丸括弧で囲むとより強く反映させることができます。
括弧を増やすと効果が強くなります。
例)((((red))))
倍率を数値で指定することも可能です。
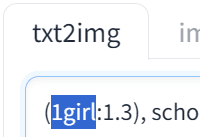
例)(red:1.2)
手入力ではなく、プロンプトを選択してCtrl+上下キーで値の増減も可能です。
・角括弧
丸括弧と逆で特定の要素を弱めることができます。
[red]
[[[[red]]]]
[red:1.2]
・プロンプトの切り替え
これは生成STEP中に使用するプロンプトを切り替えられるものです。
Stable Diffusionは徐々にノイズを取り除いて画像を生成し、Sampling Stepsがそれを何回行うかというパラメータです。
例えば20なら20回の工程を経て画像が生成されます。
[red:black:10]のように入力すると、STEP10まではred、STEP11からはblackを使うという切り替えが可能です。
・AND
大文字のANDを使うと二つの要素を融合させることができます。
例えば「apple AND chair」と入力すると、りんごと椅子を融合したような画像が生成できます。
・BREAK
BREAKはプロンプトを区切って、他の要素と干渉させにくくするものです。
例えば髪色をblack hair、服の色をred clothesのようにした場合、お互いの色が混ざってしまう場合があります。
これを防ぐために「black hair, BREAK red clothes」のようにすることで、色の干渉を防ぐ効果が得られます。
なお、プロンプトは75トークンで1つのチャンクとしてカウントされます。
1トークンはプロンプト1つのことで、チャンクはプロンプトを分割して処理できる単位です。
75トークン以上になると自動的にチャンクが2つに分かれます。
プロンプト入力欄の右上を見ると、75を超えたタイミングで分母が増えているのがわかると思います。

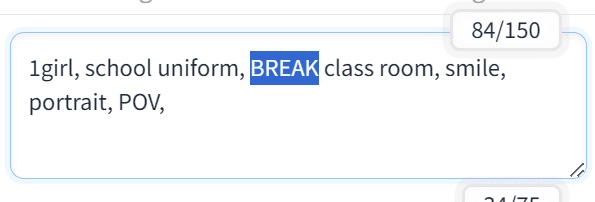
このチャンクを任意の場所で分割できるのがBREAKです。
75トークンに届いていなくても、BREAKを使うとその時点で分母が増え、チャンクが2つになります。
SD1.5モデルだと特定のカテゴリのプロンプトを1つのチャンクに入れて、分割する方が多いようです。
例)人物像, BREAK 服装, BREAK ポーズ, BREAK 背景・シチュエーション
新しいモデルはBREAKなしでも比較的Promptがしっかり反映されるため、モデルに応じて使い分けてください。
各パラメータの意味
txt2imgで設定できるパラメータについて解説します。
・Sampling method
Sampling methodは、ノイズを除去するアルゴリズムを選べるものです。
使用するSamplingによって少し画像のテイストなどが変わります。

・Sampling steps
Sampling stepsは、ノイズを除去する工程を何STEPで行うかです。
STEP数が多いと高クオリティで鮮明な画像になると言われていますが、その分処理が長くなります。
モデルによって適切な値も違うので、モデルデータの詳細などがあればそちらを参照してください。
SD1.5、SDXL辺りであれば基本20~30で使う方が多いと思います。

・Hires. fix
Hires. fixは高画質化処理ができる機能です。
チェックを入れて生成すると、画像を高画質化できます。
またUpscalerの種類や倍率、Denoising strengthによってクオリティも変化します。
Upscalerは好みのもので良いです。
倍率はモデルにもよりますが大体1.5~2倍、Denoising strengthは0.4~0.6辺りで調整している方が多い印象です。
左:Hires. fixなし
右:Hires. fixあり

・Width・Height:Widthは画像の横幅、Heightは画像の縦幅です。
・Batch count:生成する画像枚数を指定できます。2の場合、1枚ずつ処理して2枚生成します。
・Batch size:一度に生成する画像枚数を指定できます。2の場合、一度の処理で2枚生成します。
・CFG Scale:生成される画像がプロンプトにどの程度従うかを制御できます。
使用プロンプト:1girl, school uniform, class room, smile, portrait, POV

・Seed:シード値はランダム性を制御するものです。
デフォルトの-1だと生成するごとにランダムの値が付き、それぞれ異なる画像が生成されます。
付与されたシード値を使って生成すると同じ画像を生成できます。
過去に生成した画像や、ネット上でメタデータが公開されている画像を再現するときに便利です。
まとめ
とりあえず基本的なtxt2imgはこの記事の操作でできると思います。
自身で好きなモデルを用意したり、拡張機能を入れたりすることで生成できる幅もどんどん広がります。
今後その他の機能についても解説記事を書く予定なので、公開出来たら別途案内いたします。
以上A1111の基本的な使い方を紹介しました。
参考になれば幸いです。

