

Apache-2.0で公開された画像生成モデル「Boogu-Image」をComfyUIで動かす手順です。
10Bのオープンモデルで、Turboなら数ステップで画像を作れて、Editを使えば「帽子を消す」みたいな指示で画像を編集できます。
Boogu-Imageとは?
Boogu-Imageは、画像生成・高速生成・画像編集を1つのファミリーにまとめた統合画像モデルです。
パラメータ数は10Bで、Base・Turbo・Editの3モデルを公開し、中国語と英語のテキスト描画に対応。
ライセンスはApache-2.0で、研究目的での利用を想定していると案内されています。
主な特徴
- 10BパラメータのオープンモデルでApache-2.0
- 生成・高速生成・編集を1ファミリーでカバー
- Turboは3〜4ステップの蒸留版で高速
- Editは指示文ベースの画像編集に対応
- 中国語・英語のテキスト描画に強い
- ComfyUIがネイティブ対応(カスタムノード不要)
3つのモデルの違い(Base・Turbo・Edit)
同じファミリーですが、用途と推奨設定が違います。
ComfyUIだとTurbo・Editのワークフローが用意されているので、画像生成だけならTurboが始めやすいです。
| モデル | 用途 | 推奨ステップ | 向いている人 |
| Turbo | テキストから画像生成(高速・フォトリアル) | 3〜4 | まず試したい人・速さ重視 |
| Base | 汎用・密なテキスト描画・微調整の土台 | 25〜50 | ファインチューニングしたい人 |
| Edit | 入力画像を指示文で編集・変換 | 25前後 | 既存画像を加工したい人 |
ライセンスと商用利用
Boogu-ImageはApache-2.0で公開されています。
Apache-2.0自体は商用利用を許可しているライセンスなので、ライセンス上は生成画像を商用に使えると考えて良さそうです。
ただ、モデルカードでは「研究目的での利用を想定」「本番運用では追加の安全対策を推奨」と書かれているので、商用で本格的に使う場合は、自身でご確認の上ご利用ください。
Boogu/Boogu-Image-0.1-Turbo · Hugging Face
ComfyUIのインストール
ComfyUIのインストールがまだの方は以下の記事を参考にインストールしてみてください。
その後、最新版にアップデートしておく必要があります。

モデルの入手と配置
モデルはComfy-Orgが再パッケージしたものを使います。
下のファイルをダウンロードして、ComfyUIの各フォルダに置いてください。
テキストエンコーダとVAEはTurbo・Base・Edit共通なので、1回ダウンロードすれば使い回せます。
| ファイル | 置き場所 | 使うモデル |
| qwen3vl_8b_fp8_scaled.safetensors | text_encoders | Turbo・Base・Edit共通 |
| ae.safetensors | vae | Turbo・Base・Edit共通 |
| boogu_image_turbo_fp8_scaled.safetensors | diffusion_models | Turbo |
| boogu_image_edit_fp8_scaled.safetensors | diffusion_models | Edit |
| boogu_image_base_fp8_scaled.safetensors | diffusion_models | Base |
フォルダの場所
- ポータブル版:ComfyUI_windows_portable\ComfyUI\models\ の中
- StabilityMatrix:Data\models\ の中
Base/Turboで画像を生成する(テキスト→画像)
ComfyUIを起動したら左上のメニューからBrowse Templates→「Boogu」で検索してワークフローを取り込んでください。
それぞれ名前の通りEditとT2I(Turbo)で分かれています。
Base用はないですが、パラメータ調整すればTurbo用のもので生成できます。
ノードの設定
TurboはText to Image (Boogu Turbo)でモデルセットして、Prompt入力でそのまま生成できます。
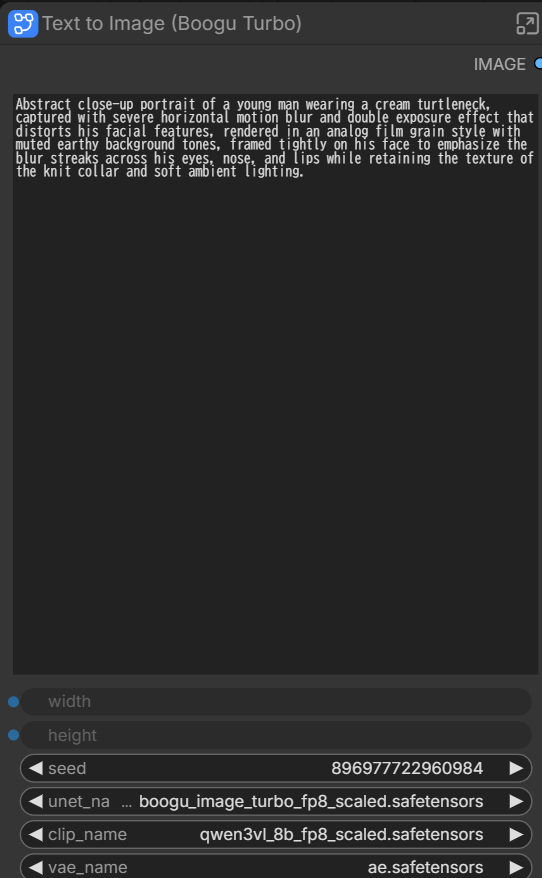
- unet_name:boogu_image_turbo_fp8_scaled.safetensors
- clip_name:qwen3vl_8b_fp8_scaled.safetensors(typeは boogu)
- vae_name:ae.safetensors
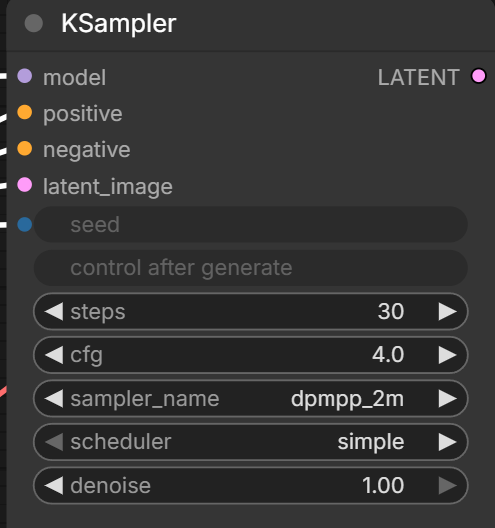
Baseは unet_name を boogu_image_base_fp8_scaled.safetensors にして、サブグラフ内にあるKSamplerでパラメータ調整してください。
蒸留してないモデルなのでEditと同じdpmpp_2m + simpleにして、steps/cfgもhugging faceで推奨されている値にします。
- steps:25~50
- CFG:2.0~5.0(例:4.0)
Promptの書き方
Boogu-Imageは、単語の羅列よりも自然な文章で書くほうが向いているそうです。
huggingfaceに載っている情報だと「何が・どんな状態で・どんな雰囲気か」を、1〜2文で素直に説明すると良いとのこと。
たとえば「Astronaut in the jungle, cool color tones, low saturation, highly detailed, 8K.」のように、被写体+色や質感+仕上がりを並べると効きます。
プロンプトは英語でも中国語でもOK。
画像の中に文字を入れたいときは、ダブルクォーテーション(””)で囲んで入れたい文言をそのままプロンプトに書きます。
生成結果
Turboは大体10秒前後でした。
・サンプル1

・サンプル2

Baseは30stepsで約1分半でした。
PromptはTurboと同じです。
・サンプル1

・サンプル2

Editで画像を編集する
Editは、入力画像に対して指示文で編集をかけるモデルです。
Edit用のワークフローを読み込んだら、unet_nameで boogu_image_edit_fp8_scaled.safetensors を選びます。
テキストエンコーダとVAEはTurboと同じものでOK。

LoadImageノードに編集したい画像を読み込み、プロンプト欄に「どう変えたいか」を英語で書きます。
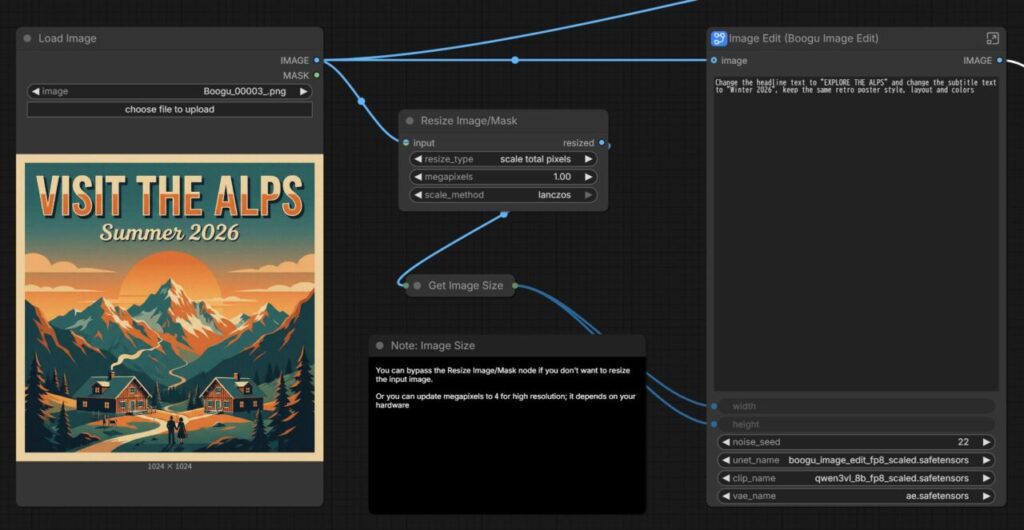
Compare Imagesは編集前後を確認できるノードです。
これはNodes 2.0専用なのでメニューからオンにしておく必要があります。
オンにするとこんな感じで編集前後の比較が可能です。
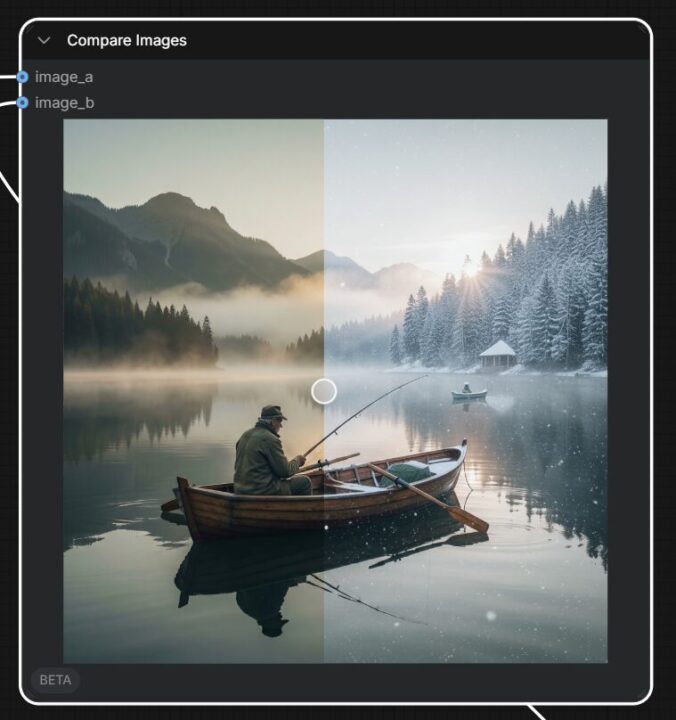
生成結果
処理は大体2分40秒くらいでした。
Turboで生成したものをそれぞれ編集したものです。
左が画像、右が編集後。
・サンプル1

・サンプル2

まとめ
Base・Turboはテキストの再現性がしっかりしていて、シンプルなPromptでもそれなりの画像が生成できます。
Editも若干処理は重いものの、クオリティは高いので、編集用途として普通に使えそうな印象でした。
用意するモデルも少ないし、簡単に高クオリティな画像が生成できるモデルなので、興味ある方は試して見てください。
以上Boogu-Imageの使い方を紹介しました。
参考になれば幸いです。

